
Principales herramientas de Big Data

En este post vamos a incluir una serie de herramientas para Big Data que, en nuestra opinión, son indispensables para el correcto tratamiento de los grandes volúmenes de datos empresariales. ¡Esperamos os sean de utilidad!
Las herramientas Big Data están en auge
Estamos asistiendo a un aumento constante de las herramientas de Big Data que hacen que nos perdamos en siglas y nombres con significados, muchas veces desconocidos para la mayoría, y que hacen que a las empresas les cueste tomar decisiones sobre qué herramientas utilizar.
Ante la actual avalancha de datos que estamos generando, a los Ingenieros en Informática y, en concreto, a los que nos especializamos en los datos, se nos generan dos problemas de índole diferente, pero que van muy unidos:
- Por un lado, nos encontramos con el problema del almacenamiento de los datos. Estos deben ser almacenados en sistemas y de maneras que podamos recuperarlos de una forma lo más sencilla y rápida posible. De nada nos sirven los datos si luego no somos capaces de encontrarlos o almacenarlos.
- Por otro, tenemos un problema con el procesamiento de los mismos. No es lo mismo, ni se utilizan las mismas técnicas, para procesar un fichero con 1000 líneas de datos (algo que podríamos hacer hasta en nuestro teléfono móvil) que procesar un fichero con 1000 millones de líneas, y el tiempo de procesado no es el mayor de nuestros problemas.
-Tal vez te interese: La importancia de la interpretación de datos-
Ante estos retos, se desarrollaron una multitud de herramientas para el almacenamiento y procesamiento de datos de forma distribuida (es decir, haciendo que múltiples ordenadores trabajen en grupo realizando cada uno una parte de la tarea). Entre las herramientas más conocidas y utilizadas se encuentran las siguientes:
Herramientas más utilizadas en Big Data
1. Apache Hadoop
Se trata de un framework de software opensource que permite el tratamiento y gestión distribuido de grandes volúmenes de información. Además del Hadoop Common (o utilidades comunes) consta de los siguientes componentes:
- Hadoop Distributed File System (HDFS): Sistema de archivos distribuido que ofrece un alto rendimiento en los accesos a los datos. Está diseñado para ser ejecutado en hardware de bajo coste y para que, su conjunto, sea tolerante a fallos y de alta disponibilidad.
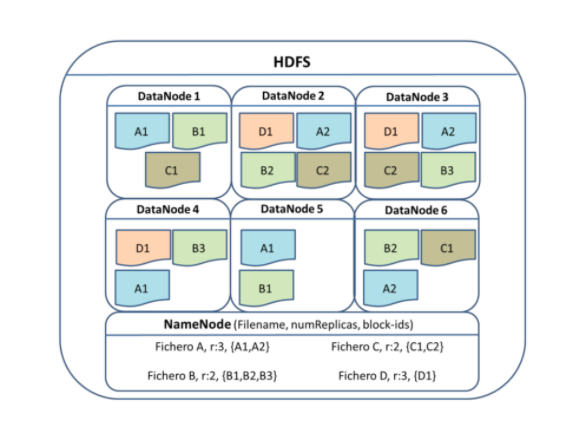
- Hadoop Yarn (Yet Another Resource Negotiator): Es un framework para gestión de recursos y planificación de tareas. Yarn combina un gestor de recursos central que gestiona la forma en que las aplicaciones utilizan los recursos del sistema, con agentes gestores en los nodos que gestionan las operaciones de proceso en los nodos individuales del clúster.
- Hadoop MapReduce: Sistema para el procesamiento en paralelo de grandes volúmenes de información. El paradigma MapReduce se emplea para resolver algunos algoritmos que son susceptibles de ser paralelizados. Se basa en realizar el procesamiento de la información en el mismo lugar en que ésta reside. Al lanzar un proceso de MapReduce, las tareas son distribuidas entre los diferentes nodos del clúster. La parte de computación se realiza de forma local en el mismo nodo que contiene los datos, por lo que se minimiza el tráfico de datos por la red y paraleliza a nivel de nodos de un cluster.
2. Apache Spark
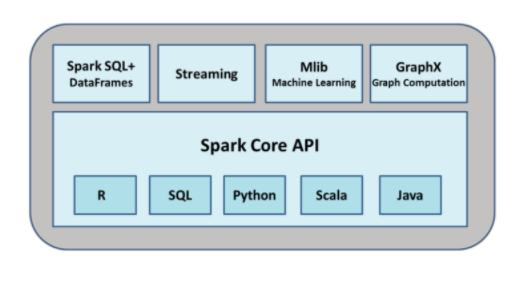
Es un framework de código abierto para computación en clúster. Ha sido desarrollado para optimizar el rendimiento, y puede resultar hasta 100x veces más rápido que que Hadoop tanto para los procesos en batch como en streaming. Se puede utilizar en diferentes lenguajes de programación (Scala, Python, R). Además, dispone de librerías específicas para trabajar con SQL, para procesar datos en streaming, para procesos de Machine Learning y para la generación de gráficos.
3. Apache Hive
Es un software para gestión de un datawarehouse de forma distribuida y que permite gestionar grandes volúmenes de datos utilizando SQL y trabajando sobre el sistema de almacenamiento de Hadoop HDFS u otros sistemas de almacenamiento distribuido como S3 de Amazon.
4. Apache Cassandra
Software opensource para la gestión de bases de datos NoSQL, construidas para manejar grandes volúmenes de información. Es un sistema con alta disponibilidad, que no tiene un único punto de fallo y que está diseñado para el procesado rápido de grandes volúmenes de información. Dispone de un lenguaje de consulta propio, Cassandra Structure Language (CQL).
5. MongoDB
Probablemente sea la base de datos de propósito general, distribuida y NoSQL más utilizada actualmente. También es open source y está orientada al almacenamiento de documentos, utilizando para ello un formato BSON (similar al JSON). Permite el sharding y las réplicas.
6. Apache Kafka
Seguramente, es la plataforma para gestión de datos distribuidos en su versión streaming más utilizada (aunque le están saliendo algunos competidores). Permite capturar la información de diferentes fuentes (IoT, bases de datos, etc.) en tiempo real para su almacenamiento, procesado o análisis. Es muy utilizado en sistemas de gestión y análisis de cookies de navegación web.
-Te puede interesar: ‘Big Data’ en el deporte para mejorar la experiencia del fan–
Ventajas de las herramientas utilizadas en Big Data
Toda esta serie de herramientas utilizadas en Big Data son de open source y pueden ser descargadas e instaladas por cualquiera (la mayoría pertenecen al proyecto Apache). Sin embargo, muchas de ellas cuentan con distribuciones específicas, donde alguna empresa se ha encargado de paquetizar la solución y simplificar la instalación, dotandolas además, de algunas herramientas para la gestión y el mantenimiento de las mismas. Este tipo de distribuciones, aunque tienen coste, nos permiten realizar despliegues rápidos y seguros, así como contar con personal especializado de apoyo y soporte.
Por supuesto, todas ellas disponen de su “reflejo” en la nube, donde la mayor parte de proveedores cloud (al menos los más grandes) nos proporcionan este tipo de infraestructuras/plataformas en su modelo “as a service” con despliegues rápidos y sencillos (basta con unos clicks de ratón) y fácil escalabilidad. Además, todas ellas obedecen al paradigma de pago por uso, lo que nos permite ajustar nuestros despliegues a nuestras necesidades de tamaño y tiempo.
-Sigue leyendo: Qué es la Inteligencia Artificial–
Conclusiones
Estas herramientas Big Data nos permiten a los encargados del tratamiento y del procesamiento de los datos en las empresas, el poder tratarlos y trabajarlos sin necesidad de disponer de grandes ordenadores dedicados a ello. Solo con un clúster de pequeños equipos, o utilizando los servicios en cloud de algunos proveedores, podemos desplegar estas herramientas para el correcto procesamiento de nuestros datos masivos.
Esperamos que esta serie de herramientas empleadas en Big Data os hayan sido de utilidad. Si tenéis cualquier duda, ¡podéis poneros en contacto con nosotros! Hasta la próxima 😊
Autor: Nacho Davó

